用于生成热力图,记录过程,方便之后直接使用。
使用场景:联邦学习中显示客户端数据分布,或者显示数据分布的各类其他场景
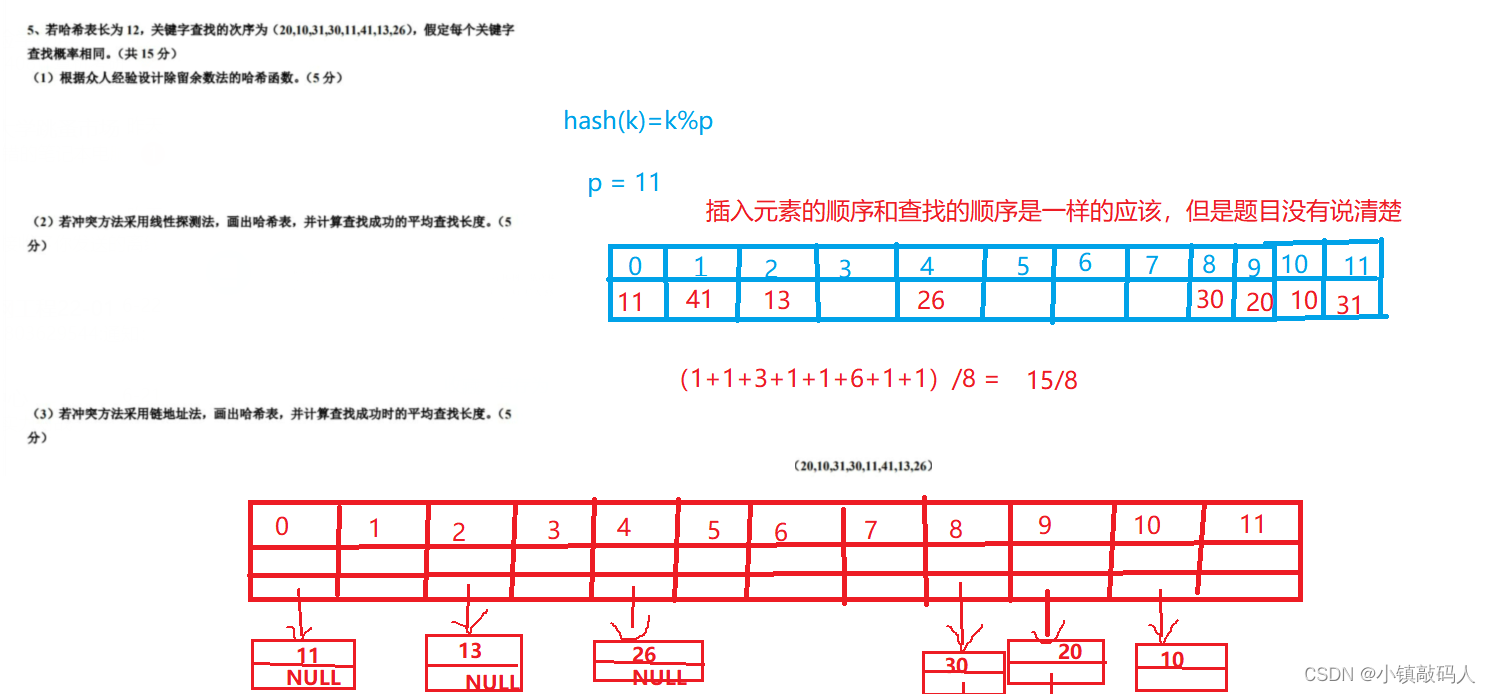
文章目录
- 一、代码
- hot.py
- 使用方法
- 二、参数解释
- 三、样图
- 关键词
一、代码
写这段代码时主要考虑联邦学习中显示客户端数据分布这一场景
hot.py
import numpy as np
import matplotlib.pyplot as plt
def hot_map(y_train, dataidx_map):
# CIFAR-10 数据集共有 10 个类别
num_classes = 10
# 有 10 个客户端
num_clients = 10
#图片中字体大小
font_size = 32
# 初始化一个矩阵来存储每个客户端的数据分布
client_data_distribution = np.zeros((num_clients, num_classes), dtype=int)
# 统计每个客户端中每个类别的样本数量
for client_id in range(num_clients):
indices = dataidx_map[client_id]
client_labels = y_train[indices]
unique_labels, label_counts = np.unique(client_labels, return_counts=True)
for label, count in zip(unique_labels, label_counts):
client_data_distribution[client_id, label] = count
# 转置矩阵,这里的转置主要是为了让横坐标是客户端,纵坐标是类标签。如果不转置,横纵坐标会交换
client_data_distribution = client_data_distribution.T
# 设置全局字体为新罗马字体
plt.rcParams["font.family"] = "Times New Roman"
# 绘制热力图
plt.figure(figsize=(10, 6))
plt.imshow(client_data_distribution, cmap='Reds', interpolation='nearest')
#设置图片标题(上方)
# plt.title('Clients Data Distribution in CIFAR-10 Dataset')
# 隐藏坐标轴的边框,更美观
ax = plt.gca()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.xlabel('Client', fontsize=font_size)
plt.ylabel('Label', fontsize=font_size)
cbar = plt.colorbar()
# 隐藏颜色条的边框
cbar.outline.set_visible(False)
cbar.ax.tick_params(labelsize=font_size) # 设置颜色条刻度标签的字体大小
plt.xticks(np.arange(num_classes), np.arange(num_classes), fontsize =font_size)
plt.yticks(np.arange(num_clients), np.arange(num_clients), fontsize=font_size)
# 设置坐标(i, j)显示的数值,可直接注释去除
for i in range(num_clients):
for j in range(num_classes):
# text((x, y)=坐标, s=数值, ha=水平对齐, va=垂直对齐, color=颜色)
plt.text(x=i, y=j, s=client_data_distribution[j][i], ha='center', va='center', color='white')
plt.tight_layout()
plt.savefig('Fig.jpg',dpi = 400, bbox_inches='tight')# bbox_inches用于在保存时将图片位于画布中间,保持紧凑;dpi是一个关于图片清晰度的参数,数值越大,图片越高清
plt.show()
使用方法
首先在需要调用热力图的地方引入文件
from hot import hot_map
接着在需要画图的地方调用,通常是刚对客户端分配好数据或者对数据分布进行处理后的位置
hot_map(y_train,net_dataidx_map)
二、参数解释
y_train:[6 9 9 … 9 1 1],就是训练数据的标签,用列表表示。
net_dataidx_map:{0:[39982, 40086, 49891, 13047, 8170, 94, 4697,],1:[…], …},这是各客户端的数据分配情况,使用字典显示,字典的键表示客户端标记,表示几号客户端;值用列表显示,列表中的各数值表示y_train的下标,举例来说,以0的39982为例,表示0号客户端包含了y_train中第39982个标签,是客户端与数据标签的映射。
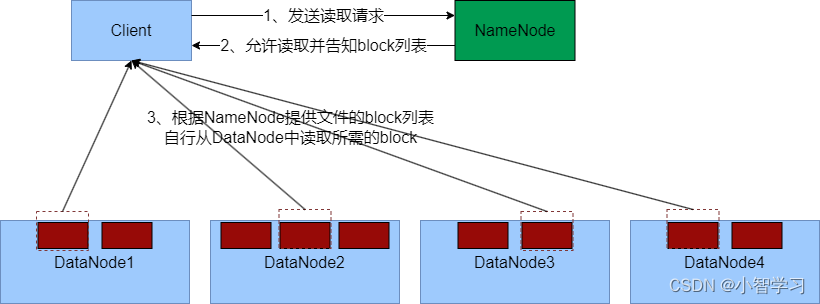
三、样图
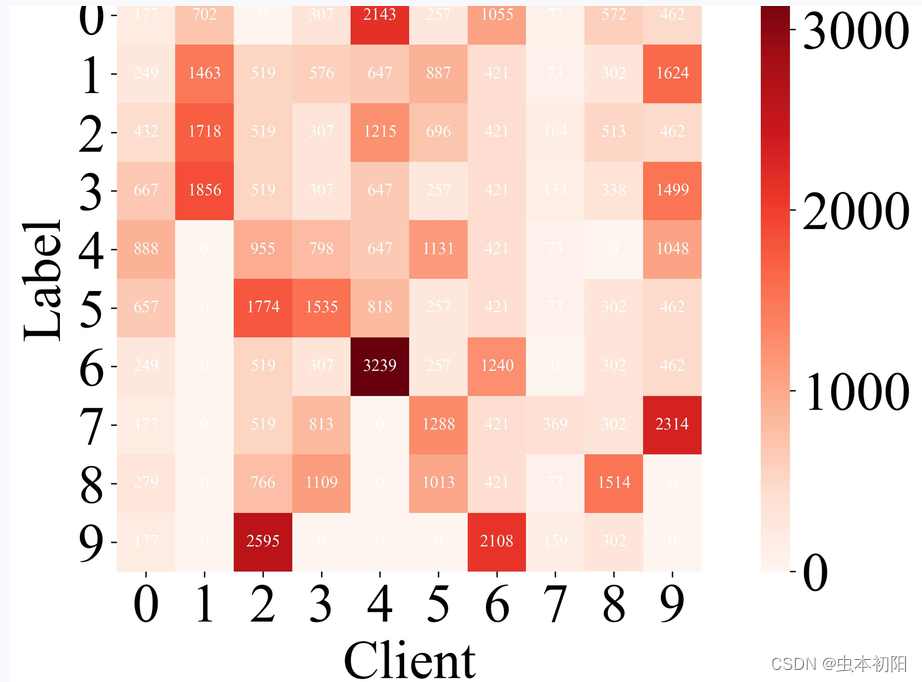
关键词
热力图; 联邦学习; 数据分布;python





![[JS]正则表达式](https://img-blog.csdnimg.cn/img_convert/778fd76ce8dc7f915d6457224766a20e.png)
